Preliminary analysis
Event storming
The event storming notation consists of the following items:
- A domain event is anything that happens that’s of interest to an SME.
- A command triggers an event.
- An aggregate accepts commands and emits events.
- A policy contains the decision on how to react to an event.
- A read model holds the information necessary to make a decision.
- A person is a human being responsible for a given decision.
- An external system is another system that interacts with the system under consideration.
- A hotspot is an unresolved item or group of items
In an event storming workshop, sticky notes of a particular color represent each of these concepts. Workshop participants place the stickies on a wall in timeline order to visualize the entire business process.
In the following, we’ll use custom symbols for these concepts, keeping the colors. This makes it easier to visualize processes.
A specific grammar governs event storming concepts [Brandolini2022], in the sense that certain things always come before or after others. It’s this grammar that allows people who aren’t domain experts to ask intelligent questions, like what emits this event?
The main part of the grammar is when a user of the system issues a command based on some information:

Some alternatives flows exist as well. An external system rather than a person may issue a command:
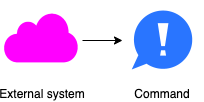
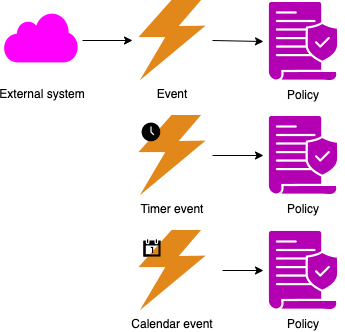
Events can also come from outside, either from an external system or from the passing of time:
Events can update read models:

With the big picture defined, we can flesh out the domain model further.
DDD and event storming give us a new vocabulary to talk about what software does. We need to reconcile that with our vocabulary of what software is.
In event storming terms, aggregates make up an application’s state. An application transitions between states when an aggregate accepts a command. The output of an application is an emitted event.
Commands and events carry data. In DDD terms, that data takes the form of domain objects.
Putting all that together, we get the following model for a software application:
flowchart TB Policy --reacts to --> Event RM[Read model] RM --based on--> Repository Application --has--> Aggregate Aggregate --emits--> Event Policy --issues--> Command Aggregate --accepts--> Command Aggregate --defined by--> RE RE[Root entity] RE --is a--> Entity RE --stored in--> Repository Entity --is a--> DO DO[Domain object] VO --is a--> DO VO[Value object] DO --contains--> DO Entity --refers to --> VO Entity --bound\ninside--> Aggregate Command --contains--> DO Event --contains--> DO Application --has--> AP AP --is a--> Policy AP[Automatic\npolicy] AP --queries--> RM PMP --is a--> Policy PMP[Person-managed\npolicy] Person --executes--> PMP Person --initiates--> Command ES --issues--> Command ES[External\nsystem] ES --emits--> Event
Design method
- Put the requirements in Rigorous Event Storming Icon Notation (RESIN) and resolve hotspots. See the examples.
- If there are any humans issuing commands, or looking at read models, then design guidelines for the user experience.
- If there are any external systems issuing commands or consuming events, then design guidelines for the developer experience.
- For all events:
- Determine whether to use a notification event or event-carried state transfer [Fowler2017]. If the latter, determine what data the event carries.
- If an external system consumes the event, design the API.
- Determine whether the event requires an explicit queue with durability guarantees.
- For all commands:
- If an external system issues the command, design the API that allows the system to do that.
- If a human issues the command, design the user interaction that allows the user to do that. This includes designing the API from the frontend to the backend.
- Determine if the command requires synchronous processing. If not, prefer asynchronous processing.
- For asynchronous commands, determine whether the command requires an explicit queue with durability guarantees.
- For all read models:
- Design the data model using ERDs or similar notation.
- If the read model serves a human, design the user interaction that gives the user access to the data.
- If the read model updates from events, determine whether each event requires an explicit queue with durability guarantees.
- For all aggregates:
- Design the data model using ERDs or similar notation.
- Create a directed graph capturing dependencies:
- Add a node for every aggregate, read model, and automatic policy.
- Add an edge from an aggregate to a policy if the policy issues a command processed by the aggregate.
- Add an edge from a policy to a read model if the policy uses the read model to make a decision.
- Add an edge from a read model to an aggregate if the read model updates from an event emitted by the aggregate.
- Assign aggregates, automatic policies, and read models to subdomains based on the above dependency graph:
- For every aggregate:
- Create a domain containing the aggregate.
- For every read model:
- If all outgoing edges of the read model are to aggregates in the same domain, assign the read model to that domain.
- Otherwise, create a domain containing the read model.
- For every policy:
- If the policy has no outgoing edges, and all commands issued by the policy go to aggregates in a single domain, assign the policy to that domain.
- If a policy has outgoing edges, and they’re all to read models in the same domain, assign the policy to that domain.
- Otherwise, create a domain containing the policy.
- For every aggregate:
- Assign commands and events to the discovered subdomains as follows:
- Assign each command to the subdomain that contains the aggregate that accepts the command.
- Assign each event to the subdomain that contains the aggregate that emits the event.
- Assign each unassigned event to the subdomain that contains the policy that handles the event.
- Dependencies between modules follow from dependencies between the RESIN elements, in particular events and commands, since those are the modules’ APIs.
- If there are cycles between modules, then merge all the modules on each cycle into a single module.
Architecture
A module is a compiled and packaged subdomain, like a jar file. A component is an executable and deployable collection of modules, like a war file or executable fat jar.
— [Richardson2023]
Architecting consists of the following activities:
- Combine modules into components based on organizational structure and Quality Attribute Requirements [Richardson2023].
- Divide components into standard components to acquire (like databases and queues) and custom components to build.
- Select existing implementations for standard components.
- Decide how components interact.
- Select technologies to implement custom components and their interfaces.
flowchart TB R[Requirement] M[Module] C[Component] SC[Standard\ncomponent] CC[Custom\ncomponent] I[Interface] T[Technology] R --implemented by--> M M --deployed in--> C C --uses--> T I --uses--> T SC --is a--> C CC --is a--> C C --provides--> I C --requires--> I
Inputs to the architecting process:
- Requirements and the modules discovered from them
- Architectural styles and patterns
- Sanctioned technologies and vendors
- Teams and their skill levels
Outputs of the architecting process:
- Assignments of modules to components.
- Container diagram. Note that the C4 model uses different terminology: their container corresponds to our component and their component corresponds to our module.
- Architecture Decision Records (ADRs).
The starting point is an application consisting of a single system. Then analyze the quality attributes one by one to see if systems need splitting. Only make the architecture as complicated as it needs to be to meet the requirements.
Performance / scalability:
- Each aggregate and policy has implied queues for accepting commands and handling events. In theory, we can use queueing theory to analyze such systems. In practice, this approach runs into some issues, like unknown arrival and service time distributions. The theoretical models usually assume that work for server processes is independent and can therefore occur in parallel. In practice, this is seldom the case, and Amdahl’s law comes into play [Amdahl1967]. These problems mean that mathematical analysis is usually computationally intractable or at least impractical. It’s best to measure arrival and service times, store these as metrics, and then scale dynamically based on the collected metrics.
- Some commands require synchronous processing, because the caller needs a result right away. The latency for processing such commands is the latency of the entire process. For asynchronous commands, the latency is just the work for validating the input. Use asynchronous commands where possible, to give faster feedback.
- Split off command/event handlers that have significantly different scaling requirements into their own components, so they can scale independently.
Resilience:
- Make some queues explicit as components so that retries can handle issues during processing of commands/events. This requires that the handling code is idempotent.
- Split off command/event handlers that have a big risk of causing issues, like OOM, to reduce impact on other parts.
- Define what liveness means for each process. Consider using an orchestration tool (another component) to automatically restart processes that fail the liveness test.
- Consider load shedding when performance requirements aren’t met to preserve uptime. Detect this using the metrics defined in these requirements.
Security / compatibility:
- Commands arrive over a wire protocol. Apply input validation while mapping their data to domain objects.
- Apply output encoding when mapping domain objects to outputs.
Maintainability / portability:
- The domain model is more stable than technical parts, like what storage solution to use. Apply hexagonal architecture to isolate changes in those parts from the domain model.
Once done with quality attribute requirements, you should have identified all components. Perform make or buy decisions on all components. For each custom component, implement all functional requirements in the requirements group implemented by the component. Again, do one requirement at a time. Quality attribute requirements apply to all components.
Design
Design happens for each custom component:
- Collect all requirements in the requirements group that the custom component must implement.
- Implement requirements one at a time.
- For a given requirement, translate its acceptance tests into a list of detailed tests.
- Write code based on those tests using TDD.
flowchart BT R[Requirement] RG[Requirements\ngroup] CC[Custom\ncomponent] I[Interface] AT[Acceptance\ntest] UT[Unit test] C[Code] PL[Programming\nlanguage] T[Technology] AT --specifies--> R UT --implements\npart of--> AT UT --validates--> C C --implements--> CC C --implements--> I CC --implements--> RG R --is part of--> RG CC --provides--> I CC --requires--> I C --written in--> PL UT --written in--> PL PL --is a--> T
Canon TDD:
- Write a list of the test scenarios you want to cover.
- Turn one item of the list into an actual, concrete, runnable test.
- Change the code to make the test (& all previous tests) pass (adding items to the list as you discover them).
- Optionally refactor to improve the implementation design.
- If the test list isn’t empty, go back to #2.
Issues:
- How to order the initial list of tests? Select one which requires the code transformation with the highest priority.
- How to design the code-level API when writing a test? How to test quality attribute requirements?
- Are the transformations in the TPP complete?
- How to perform the vague ones, like
statement->statements? - How to deal with big jumps?
- Is there an order to code smells as well?
- When should we fix a smell and when should we wait a bit?